每日LeetCode算法刷题归纳和总结
比较复杂的场景有矩阵情况
BFS/DFS
顺序 二分 差值 斐波那契查找
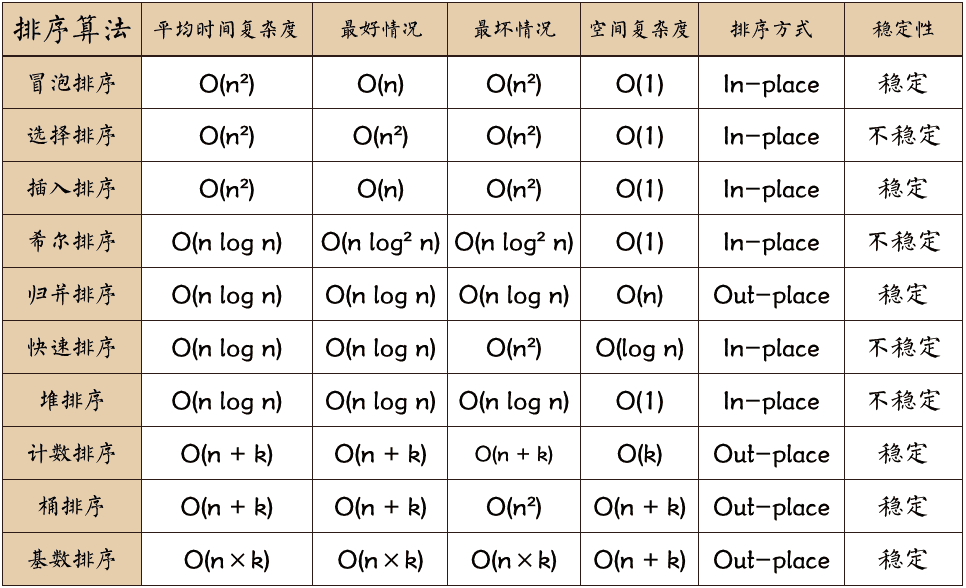
冒泡 选择 插入 希尔 快排 归并 堆排序 桶排序 基数排序
头尾双指针 STEP步长不同的双指针 指针确定范围
通过组合子问题的解来来求解原问题 即不同的子问题具有公共的子子问题(子问题的求解是递归进行的,将其划分为更小的子子问题) 而动态规划对于每一个子子问题只求解一次,将其解保存在一个表格里面,从而无需每次求解一个子子问题时都重新计算,避免了不必要的计算工作 通常是通过容器Map Set 数组 甚至可以为临时变量 存放计算结果 通常边界数据 0 1 等初始数据会在一开始将结果放入容器 并递推计算得到结果 避免无限递归
我们解决动态规划问题一般分为四步: 1、定义一个状态,这是一个最优解的结构特征 “状态”是指解决某一问题的中间结果,它是子问题的一个抽象定义。 这个是最重要也是最难的 怎么定义状态 帮助我们解决问题 并且存在递推可能 2、进行状态递推,得到递推公式 而“状态转移方程”是指状态与状态之间的递推关系。 3、进行初始化 4、返回结果
这是大多数文章和教材说的动态规划的解法 比较抽象 将其具像化便于理解
比如斐波那契数列 定义状态f(i)表示 第i个数列的结果 初始化情况 f(0) = 0 f(1) = 1 f(2) = 1 然后进行状态递推f(i) = f(i-1) + f(i-2) 返回结果f(i)
代码表示 声明map map = new HashMap() map[0] = 0; map[1] = 1; map[2] = 1; map[i] = result; 循环递推 for(int i=2;i 小于 n;i++){ f[i] = f[i-1]+f[i-2] map[i] = f[i] //保存结果 } return map[n]

动态规划还有着非常有趣的应用 上图我们理解动态规划像一棵树 存储着中间步骤的计算结果 如果我们把 [0, n-1][0,n−1] 分治下去出现的所有子区间的信息都用堆式存储的方式记忆化下来,即建成一颗真正的树之后, 我们就可以在 O(\log n)O(logn) 的时间内求到任意区间内的答案,我们甚至可以修改序列中的值,做一些简单的维护, 之后仍然可以在 O(\log n)O(logn) 的时间内求到任意区间内的答案, 对于大规模查询的情况下,这种方法的优势便体现了出来。这棵树就是上文提及的一种神奇的数据结构——线段树。
通过组合子问题的解来来求解原问题 分治方法将问题划分为互不相交的子问题,递归的求解子问题,再将它们的解组合起来 求出原问题的解
分治法解题的一般步骤: (1)分解,将要解决的问题划分成若干规模较小的同类问题; (2)求解,当子问题划分得足够小时,用较简单的方法解决; (3)合并,按原问题的要求,将子问题的解逐层合并构成原问题的解。
指针是关键 双指针的应用非常多
需要熟练掌握& nor 与 或 异或等运算
非常重要的数据结构 DFS/BFS 先中后三序 层次遍历 等算法应用
需要着重不同栈的组合使用 利用栈反转的特性